
 С помощью Docker можно быстро развернуть рабочее web приложение с различными настройками и версиями. Docker Swarm выступает инструментом «оркестрации» контейнеров Docker, который позволяет управлять контейнерами как единое целое.
С помощью Docker можно быстро развернуть рабочее web приложение с различными настройками и версиями. Docker Swarm выступает инструментом «оркестрации» контейнеров Docker, который позволяет управлять контейнерами как единое целое.
Использование Docker Swarm orchestrator - отличный (и относительно простой) способ развертывания контейнерного кластера. Да, вы могли бы использовать Kubernetes для получения дополнительных возможностей управления, но когда вам нужны базовые элементы простого контейнерного кластера, Docker Swarm - отличный вариант.
Что вам понадобится
Я продемонстрирую на примере небольшого кластера с одним ведущим и двумя узлами, каждый из которых будет работать на Ubuntu Server 22.04.
Итак, для этого вам понадобятся:
- Три запущенных и обновленных экземпляра Ubuntu Server 22.04.
- Пользователь с привилегиями sudo.
- Это все, что вам нужно, чтобы все заработало.
В некоторой литературе рекомендуют использовать 3 или 5 управляющих узлов, что связано с алгоритмом в Swarm, определяющим его отказоустойчивость, в нашем случае будут один управляющий узел (manager) и два рабочих (workers). Для просмотра текущих узлов можно использовать команду «docker node ls» (https://docs.docker.com/engine/swarm/raft/).
Рассмотрим основные функции Docker Swarm:
- Регулирование масштабом приложения, количеством реплик;
- Не требуется отдельного приложения для оркестрации приложения. Docker Swarm является встроенным инструментом оркестрации в Dcoker;
- Готовая оверлейная сеть;
- Docker Swarm используется встроенную систему безопасности TLS Transport Layer Security - протокол защиты транспортного уровня для аутентификации и шифрования данных между узлами.
- Последовательная система обновления узлов (nodes), Docker Swarm позволяет обновления последовательно передавать на отдельные node.
Создание и настройка кластера Swarm
И так, зайдем в терминал ssh -o "ServerAliveInterval 60" root@xx.xxx.xxx.xx
Прежде чем запустить docker swarm не забудьте открыть порты (2377, 7946, 4789)
Для запуска docker swarm необходимо выполнить следующую команду:
docker swarm init --advertise-addr 100.255.13.35:2377 --listen-addr 100.255.13.35:2377
Формат --advertise-addr --listen-addr 0.0.0.0:2377. Подробные настройки этой находятся на https://docs.docker.com/reference/cli/docker/swarm/init/
После запуска скопируйте команду отображаемую на экране, которая выглядит примерно следующим образом:
docker swarm join --token SWMTKN-1-3pu6hszjas19xyp7ghgosyx9k8atbfcr8p2is99znpy26u2lkl-7p73s1dx5in4tatdymyhg9hu2 192.168.99.121:2377
Давайте войдем на рабочий узел и введем указанную команду, её необходимо запустить на каждому рабочем узле, который присоединяется к кластеру docker swarm.
И это все, что нужно для развертывания swarm.
Перейдите на рабочую машину (manager), создайте рабочую директорию.
mkdir /root/swarmtest/
Пусть она называется «/root/swarmtest» (cd /root/swarmtest/).
В ней будут созданы следующие файлы docker-compose.yaml, директория nginx.
services:
web1:
image: nginx
ports:
- 8081:80
deploy:
replicas: 3
resources:
limits:
cpus: '0.1'
memory: 200M
placement:
constraints:
- "node.labels.TAG==stage"
#configs:
#- source: nginx_config
# target: /etc/nginx/conf.d/default.conf
volumes:
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf:ro
- /gluster/volume1/www:/var/www
web2:
image: httpd
ports:
- 8082:80
deploy:
replicas: 2
php:
image: php:8.2-fpm
ports:
- 9001:9001
deploy:
replicas: 2
resources:
limits:
cpus: '0.1'
memory: 200M
volumes:
#- /mnt:/var/www
- /gluster/volume1/www:/var/www
configs:
app_config:
external: true
nginx_config:
external: true
Указанный файл создается исключительно на управляющем хосте.
В этом файле создаются три сервиса: web1 (отвечает за сервер nginx), web2 (отвечает за сервер httpd), php (для proxy nginx).
Подробное опишу каждое значение строк данного файла:
image — образ nginx из которого создается контейнер nginx.
ports — порт для доступа к нашему nginx.
Особое значение для этой секции отведем:
deploy:
replicas: 3
resources:
limits:
cpus: '0.1'
memory: 200M
placement:
constraints:
- "node.labels.TAG==stage"
Секция deploy отвечает за выполнение команды «docker stack deploy» (https://docs.docker.com/reference/cli/docker/stack/deploy/).
Мы будем запускать наш стэк следующей командой:
docker stack deploy --compose-file docker-compose.yml swarmtest
Это команда управления кластером, которая должна выполняться на узле swarm manager.
Команда для удаления кластера
docker stack rm swarmtest
Далее можно запустить команду для вывода информации о всех сервисах
docker service ls:

Из них первая, сервис с нашим регистром, со второй по четвертую - сервисы запуска контейнеров с nginx и httpd, php.
Последний сервис поможет визуализировать кластер в браузере.
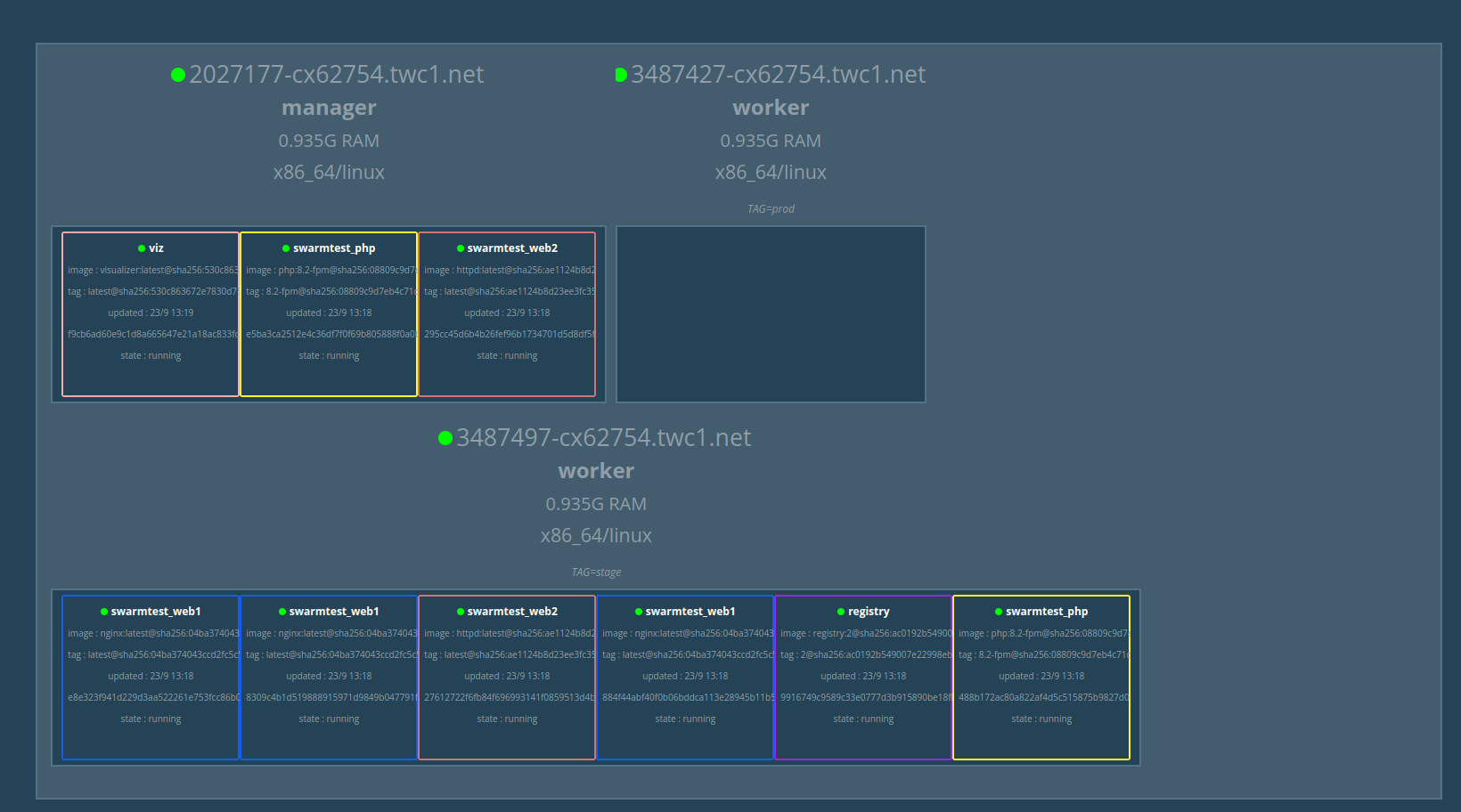
Рис. 1:
Для установки visualizer из образа:
docker service create \
--name=viz \
--publish=8080:8080 \
--constraint=node.role==manager \
--mount=type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock \
dockersamples/visualizer
Без использования вам понадобится команда docker container ls. К примеру если запустить ее на одной из node то можно получить следующую информацию о контейнерах с подробной информацией:

Следующий код копирует файлы при запуске сервиса на каждый хост (node):
volumes:
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf:ro
- /gluster/volume1/www:/var/www
Он не в прямом смысле копирует файлы с управляющего хоста на рабочие, а в переносном. Эти файлы должны существовать физически на каждом хосте, не только на рабочем.
Можно сказать, что это достаточно нудно каждый раз обновлять данные на трех разных серверах. Поэтому для решения этой проблемы мы воспользуемся GlusterFS. GlusterFS — распределённая, параллельная, линейно масштабируемая файловая система с возможностью защиты от сбоев.
GlusterFS
GlusterFS можно использовать с кластером Docker Swarm для репликации томов. Это позволяет сделать данные доступными для всех нод в любое время. При этом для каждого Docker-хоста именованные тома останутся локальными.
Для любого разработчика контейнеров постоянное хранилище часто является обязательным инструментом. С помощью некоторых контейнерных технологий постоянное хранилище может быть создано довольно просто. Хотя в Docker вы можете использовать тома, проблема с этой функцией заключается в том, что это локальная система. Из-за этого вам необходимо использовать стороннее программное обеспечение, такое как NFS или GlusterFS. Большой недостаток NFS в том, что она не зашифрована. Поэтому для многих компаний и разработчиков GlusterFS - это правильный выбор.
Поэтому, я хочу рассказать вам о процессе использования GlusterFS для совместного использования постоянного хранилища в Docker Swarm.
Итак давайте настроим GlusterFS.
sudo apt-get update
sudo apt-get upgrade –y
Добавьте свои хосты
Теперь нам нужно сопоставить наши IP-адреса в /etc/hosts. Сделайте это на каждом компьютере. Выполните команду:
sudo vi /etc/hosts
Укажите свои ip:
192.168.1.67 docker-master
192.168.1.107 docker-node1
192.168.1.117 docker-node2
Разверните Swarm
Если вы еще этого не сделали, вам необходимо установить и развернуть Docker Swarm. На каждом компьютере установите Docker с помощью команды:
sudo apt-get install docker.io –y
sudo systemctl start docker
sudo usermod -aG docker $USER
Если вы не выполнили ранее выполните команду docker swarm join –token
Теперь вам нужно установить GlusterFS на каждый сервер в swarm. Сначала установите необходимые зависимости с помощью команды:
sudo apt-get install software-properties-common –y
sudo add-apt-repository ppa:gluster/glusterfs-3.12
sudo apt-get update
Установите сервер GlusterFS с помощью команды:
sudo apt install glusterfs-server –y
sudo systemctl start glusterd
sudo systemctl enable glusterd
Сгенерируйте SSH-ключи
Если вы еще этого не сделали, вам следует сгенерировать SSH-ключ для каждой машины. Для этого выполните команду:
ssh-keygen -t rsa
Проверка узлов
Теперь мы попросим Gluster проверить все узлы. Это будет сделано с помощью мастера. Я собираюсь придерживаться моего примера с двумя узлами, которые являются docker-node1 и docker-node2. Прежде чем вы введете команду, вам нужно будет переключиться на режим суперпользователя:
sudo –s
Если вы не запустите команду Gluster probe из root, вы получите сообщение об ошибке, которое не может быть записано в журналы. Команда probe выглядит следующим образом:
gluster peer probe docker-node1; gluster peer probe docker-node2;
Обязательно отредактируйте команду в соответствии с вашей конфигурацией (для имен хостов).
После завершения выполнения команды вы можете проверить, подключены ли ваши узлы к команде:
gluster pool list
Вы должны увидеть все узлы, перечисленные как подключенные (рис. 2).

Рис 2.
Выйдите из системы root-пользователя с помощью команды exit.
Создайте том Gluster
Давайте создадим каталог, который будет использоваться для тома Gluster. Эта же команда будет запущена на всех компьютерах:
sudo mkdir -p /gluster/volume1
Используйте любое имя, которое вы хотите, вместо volume1.
Теперь мы создадим том в кластере с помощью команды (запускается только на главном сервере).:
sudo gluster volume create staging-gfs replica 3 docker-master:/gluster/volume1 docker-node1:/gluster/volume1 docker-node2:/gluster/volume1 force
Запустите том с помощью команды:
sudo gluster volume start staging-gfs
Том теперь запущен, но нам нужно убедиться, что он будет подключен после перезагрузки (или при других обстоятельствах). Мы подключим том к каталогу /mnt. Для этого выполните следующие команды на всех компьютерах:
sudo -s
echo 'localhost:/staging-gfs /mnt glusterfs defaults,_netdev,backupvolfile-server=localhost 0 0' >> /etc/fstab
mount.glusterfs localhost:/staging-gfs /mnt
chown -R root:docker /mnt
exit
Чтобы убедиться, в что том, что Gluster установлен, выполните команду:
df -h
Она должна отображаться в списке посередине(рисунок 3).
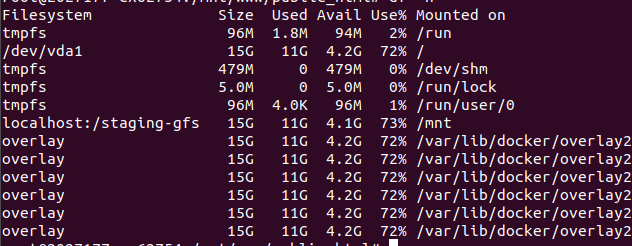
Рис 3.
Теперь вы можете создавать новые файлы в каталоге /mnt, и они будут отображаться в каталогах /gluster/volume1 на каждом компьютере.
Итак сервис Gluster настроен, дальше надо это добавить в файл docker-compose.yaml для подключения в томах docker:
volumes:
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf:ro
- /gluster/volume1/www:/var/www
volumes:
- /gluster/volume1/www:/var/www
Без этого, контейнеры не будут отрабатывать как положено для сервисов nginx и php.
Поскольку мы подключили наше постоянное хранилище в /mnt, все, что сохранено там на одном узле docker, будет синхронизировано со всеми остальными узлами. Именно так вы можете создать постоянное хранилище и затем использовать его в кластере Docker Swarm. Конечно, это не единственный способ обеспечить работу постоянного хранилища, но он один из самых простых (и дешевых). Попробуйте использовать GlusterFS в качестве опции постоянного хранилища и посмотрите, не сработает ли он у вас.
Надеюсь, пока все понятно.
Nginx и PHP
Сервер nginx будет обрабатывать поступающие запросы и передавать их PHP.
Конфигурационный файл nginx default.conf следующим:
server {
listen 80;
#server_name ;
root /var/www/public_html;
#error_log /var/log/nginx/error.log;
#access_log /var/www/app/log/nginx/access.log;
client_max_body_size 100m;
location / {
index index.php index.html;
}
location ~ \.php$ {
include fastcgi_params;
fastcgi_pass php:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root/$fastcgi_script_name;
}
}
Указанный файл необходимо разместить на всех узлах.
Давайте для простоты теста добавим в секцию web1 следующий код:
placement:
constraints:
- "node.labels.TAG==stage"
Swarm по умолчанию развертывает сервисы на любой доступной ноде или на нескольких нодах, но как правило нам необходимо развертывать их на конкретной ноде или на специфической группе. И тут нам помогут labels.
Они помогут запускать nginx только на указанном хосте, привязанном к ярлыку «stage» . Для его работы надо создать ярлык для хоста следующей командой:
docker node update –label-add
к примеру присвоим хостам ярлыки (используйте команду docker node ls ддя определения вашего название хоста из столбца HOSTNAME, они могут отличаться, например у меня 2027177-cx62754.tw.net ):
docker node update --label-add TAG=stage stage
docker node update --label-add TAG=prod prod-1
Вы спросите: зачем нам это нужно? К примеру, у нас есть рабочий проект «prod» и для тестирования «stage». Перед тем как заменить код на рабочем проект, желательно его протестировать в stage.
Теперь осталось вернутся к коду:
placement:
constraints:
- "node.labels.TAG==stage"
Указанный код фактически ограничивает развертывание реплик контейнеров на определённой node, в нашем случае web1.
Почти все, осталось создать файл index.php директории /mnt/, который будут передан на рабочие хосты в директорию /glusters/volume1/var/www/public_html. Помните мы ранее создали GlusterFS, то есть файлы содержащиеся в директории mnt/ автоматически появляются на рабочих хостах в одной и той же директории /glusters/volume1/, которая в свою очередь помещает файлы в контейнеры по адресу /var/www/ (строка файлы docker-compose.yaml), поскольку в Docker Swarm отсутствует встроенная возможность дублирования файлов на рабочие хосты.
<?php
echo '<h2>hello title</h2>';
echo '<p>hello world <br/>';
echo '<p style="float:left;">
<img src="http://xxx.xxx.xx.xxx/b59fbe24-shutterstock_1925713271.jpg" alt="Docker Swarm и Nginx и PHP. вебсервер в кластере Docker Swarm" width="620" height="414"></p>
';
?>
поместим в нашу публичную директорию файл:
scp /home/alex/Загрузки/benjamin-voros-phIFdC6lA4E-unsplash.jpg root@xxx.xxx.xx.xxx:/mnt/www/public_html/
Сейчас по адресу http://ваш ip:8081 будет доступен сайт.

Итак, мы рассмотрели Docker Swarm как он помогает обеспечить высокую доступность посредством создания кластера, если отказывает один узел продолжает выполнятся другой.
Давайте, закомментируем:
placement:
constraints:
- "node.labels.TAG==stage"
и посмотрим что будет на схеме visualizer.
565 просмотров
Взаимосвязанные материалы
Типичный пример быстрой настройки Docker и Nginx c доступом по https. читать...
Небольшая статья - продолжение предыдущих трёх статей:
читать...Продолжаем настройку кластера Swarm. В этой статье мы попробуем добавить Traefik к уже существующему стэку Docker Swarm. читать...
Docker Swarm и Nginx, PHP. Вебсервер в кластере Docker Swarm. Часть 2. Mysql. В этой статье мы попробуем добавить сервер mysql к уже существующему стэку Docker Swarm. читать...
С помощью Docker можно быстро развернуть рабочее web приложение с различными настройками и версиями. Docker Swarm выступает инструментом «оркестрации» контейнеров Docker, который позволяет управлять контейнерами как единое целое. читать...